

By: Joy Singh
Joy Singh is a ThM student at Dallas Theological Seminary. He worked as a graduate student intern at the Center for the Study of New Testament Manuscripts in 2019–2020. His internship research project focused on fragmentary medieval manuscripts. This blog is derived from that research project.
The discovery of New Testament Greek manuscripts has proliferated since the dawn of the twentieth century. But with the gust of manuscript discoveries, the burden of maintaining a sacrosanct process of cataloguing these manuscripts has fallen on team INTF in Münster. When a manuscript is discovered, INTF is notified and provided with images and as much bibliographical detail as possible. Then incomplete manuscripts are checked to see if they belong to a portion of another manuscript already assigned a Gregory-Aland (GA) number. Unique manuscripts are assigned their own numbers, and missing pieces are included under the existing entry.
If only the process was as easy as it seems. Many manuscripts, due to their inherent value and profiteering sellers, have often been disassembled and sold as pieces. Fragments of the same codex can be found in different parts of the world and have been discovered at different times. The task of comparing each manuscript with the ones catalogued before is hard, even with the available technology. Text critics in the past have discovered fragments belonging to the same codex that were given unique GA numbers. One of the more famous cases of such discovery was accepting P4 to be a part of P64+67.
It should make one wonder if there are other accidental duplicates with unique GA numbers belonging to the same codex. While it is comparatively easy to look through 140 papyri and even 323 majuscules recorded in the Liste for a match, looking for a match in 2956 minuscule entries is like looking for a needle in a haystack.
The need to conduct this search is necessary for two reasons. First, it will give us a more accurate count of manuscripts. Second and more importantly, finding additional fragments will give the textual critics more data to work with in order to ascertain the scribal habits and a better chance of ascertaining its textual character.
As a part of my research at CSNTM, I ventured to look for matches among the minuscules. INTF’s search tools provide different parameters to narrow the search—columns, lines, height, width, content, and the image source if the listing has an image. To have a manageable project for my research, I narrowed the date range to 1100–1499 CE and only considered manuscripts with available images.
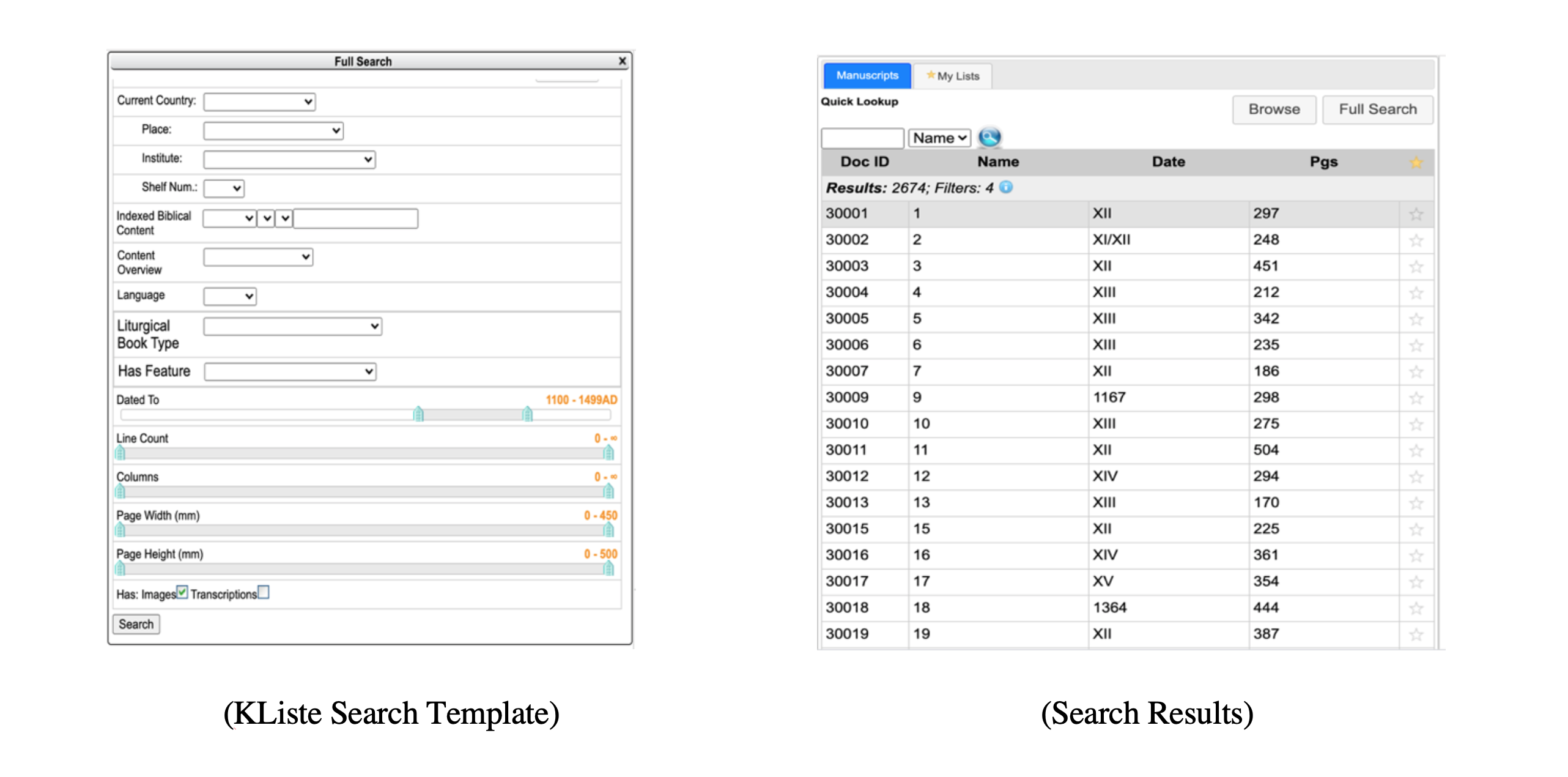
Manuscripts containing single digit page numbers were selected as base manuscripts since it seems more likely for a single page or a handful of pages to be sold separately or distributed than larger sections. I will illustrate one case to demonstrate my process of trying to find potential matches for these fragmented minuscules.
For our purpose, we will look at the case study of GA 2010. This manuscript is a 14th-century eight-page gathering of Romans written on paper located at the Trinity College, Dublin. The document was written with one column of 25 lines, and the paper dimensions are 215 mm height by 140 mm width. My search for other manuscripts with similar characteristics of GA 2010 yielded five results. These were GA 969, 1236, 1537, 2900, and 2942.
The only potentially close match was GA 2900. Manuscript 2900 is a 14th-century manuscript containing the Gospels, located at the Albanian National Archives, digitized by CSNTM. The measurements are nearly an exact match with GA 2010, with only a minor difference in width. In addition, GA 2900 does not have covers that could indicate whether it once contained more than just the Gospels. There were other common features such as enlarged letters at the beginning of sections, pagination, and other marginalia.
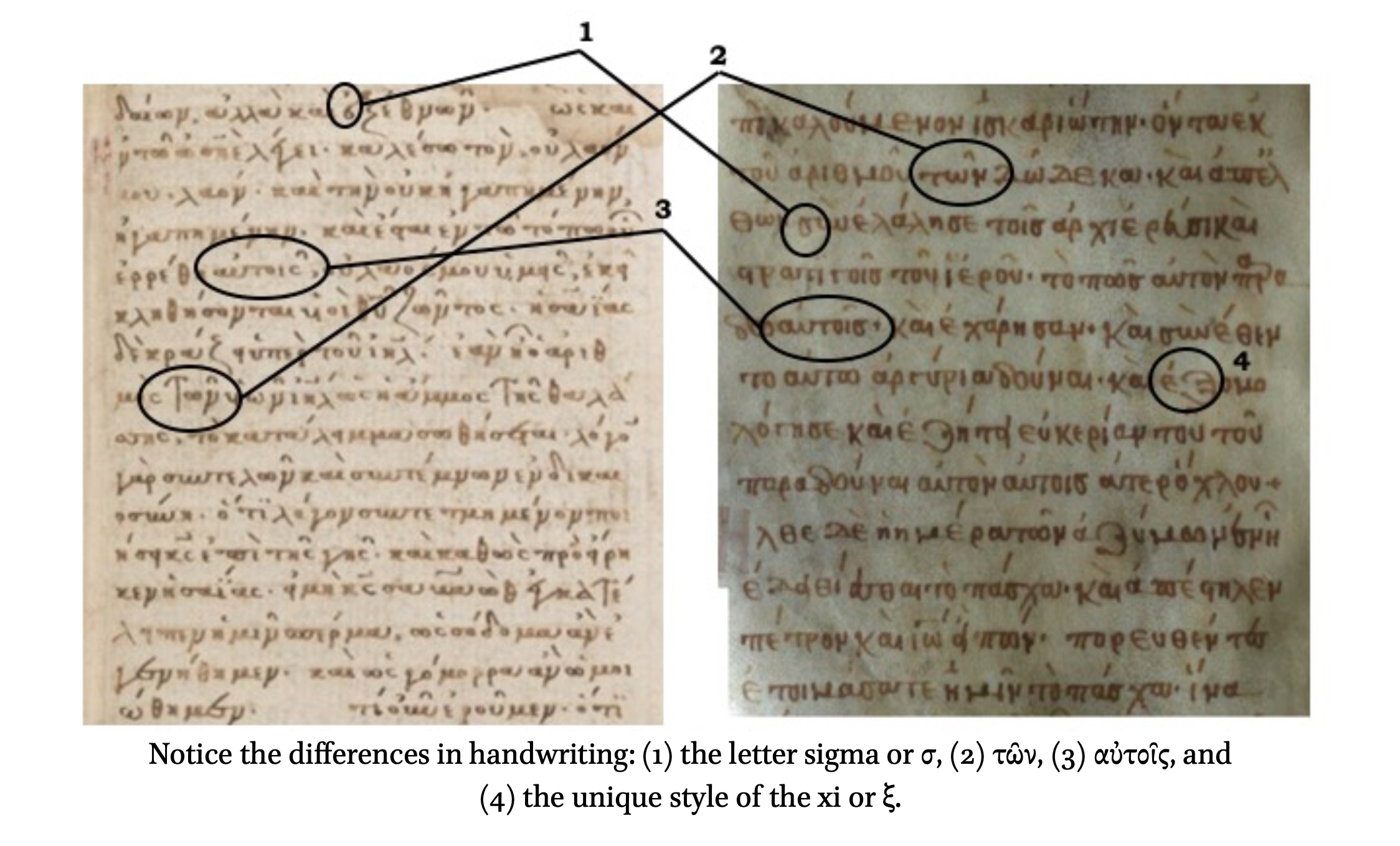
But we are quickly able to determine that GA 2010 was not a part of GA 2900 by looking at the scribe’s handwriting. The letters are formed in different ways in each manuscript. For example, the end sigma in the pronoun ?????? is different in the two manuscripts. The article ??? is written differently. And the preposition ?? is drawn differently. These are highlighted in the image below.
In addition to this case, I examined four other fragmentary minuscules to see if I could find a match: 1284, 2286, 2124, 2588. In total, thirty-six manuscripts came close to the search parameters of the four base manuscripts. Twenty out of the thirty-six manuscripts did not have images. And some that had images were difficult to read from microfilms. Within the time period 1100–1499 CE, INTF has 3545 manuscripts catalogued out of which 859 manuscripts do not have any images—microfilm or digital. And the number of manuscripts with older low-quality images creates barriers for studying some of those that do have images. It is possible that we do have duplicate entries in our collective list of New Testament manuscripts, but we do not yet have the necessary element to confirm all possibilities—that is, high quality digital images.
CSNTM’s work to digitize manuscripts is critical and foundational to the effective study, analysis, and knowledge of the manuscripts. This is, of course, also true for the imaging work other libraries and institutes are doing. Without clear digital images, a manuscript’s value is primarily as an antique for the majority of scholars. The cost of digitization and online access is fractional compared to what it would cost for every person engaged in text critical research to physically access these manuscripts scattered around the globe. The partnership between library, researcher, and academic institutes like the INTF and CSNTM is crucial for a thriving study of Greek New Testament manuscripts. Having worked with and learned from CSNTM this year, I believe the Center’s mission needs ongoing support in gaining access to undigitized manuscripts.